Reward shaping对收敛效率的影响
值得注意的一点是,与一般的强化学习问题不同,该任务只在结束整个序列的决策后(即生成完整网络结构后)才会得到一个reward,而之前的每个决策是对应reward。由于获得最终reward的成本非常高(需要在数据上重新训练新获得的网络结构),为了加快它的收敛,作者使用了reward shaping的技巧(如图五所示),因而训练初始阶段终止层的Q值不会过高,超变态网页游戏大全,让算法不会在训练初始阶段倾向于生成层数过浅的网络结构。
在网络设计强化学习中,本文把当前神经网络层定义为增强学习中的目前状态(current state),而下一层结构的决策定义为增强学习中的动作(action)。这里使用之前定义的神经网络结构编码来表示每一层网络。这样,通过一系列的动作决策,就能获得一条表示block结构的编码(如图四所示),而提出的强化学习算法通过优化寻获最优的动作决策序列。本文使用Q-learning算法来进行学习,具体的公式不再展开。
图六:
即真实的reward和提前停止的准确度成正比,但是和网络结构的计算复杂度和结构连接复杂度(block中边数除以点数)成反比。通过这样的公式矫正,得到的reward对网络结构的好坏更加具备可鉴别性(如图六所示)。提前停止策略
相比之前的自动网络搜索方法(如Google NAS算法的数百块GPU以及一个月时间),BlockQNN算法可谓十分高效(如表二、表三所示)。
虽然能够使用多种技巧来使自动化网络结构设计变的更加高效。但是自动网络设计中耗费时间的关键还是在于每次获得reward的时间成本非常高,需要将生成的网络结构在对应的数据集上训练至收敛,然后获得相应的准确度来表示结构的好坏并且用作reward。本文作者发现,通过调整学习率,只需要正常训练30分之一的过程(例如,CIFAR-100数据集上训练12个epoch),就可以得到网络的大致最终精度,这样可以大大降低时间成本。但是,这样的网络结构精度及其关联的reward会有误差,导致无法精细区分网络结构的优劣,本文提出一个凭经验的解决公式:
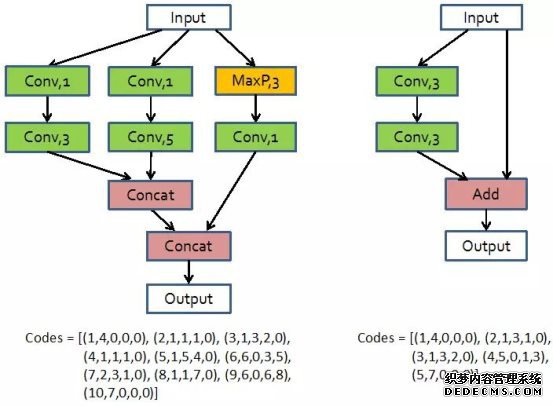
接下来的核心问题即是如何获得最优的网络结构。尽管网络结构的搜索空间已经通过设计block大大减小,但是直接暴力搜索所有可能结构,依然十分耗费计算资源。本文因此提出一种基于强化学习的网络设计方法,自动学习得到网络结构。
近期的网络结构自动设计/搜索算法通常需要耗费巨大的计算资源(例如,Google的NAS算法需要使用数百块GPU以及近一个月的训练时间),而且生成的模型可迁移性不强,难以做到真正的实用化。本文提出的BlockQNN算法能够解决现有网络结构自动设计/搜索方法效率和泛化性的问题。
