4 实验
摘要:深度神经网络在过参数化和使用大量噪声和正则化(如权重衰减和 dropout)进行训练时往往性能很好。dropout 广泛用于全连接层的正则化,但它对卷积层的效果没那么好。原因可能在于卷积层中的激活单元是空间关联的,使用 dropout 后信息仍然能够通过卷积网络传输。因此我们需要 dropout 的一种结构化变体来对卷积网络进行正则化。本论文就介绍了这样一种变体 DropBlock,它会丢弃特征图相邻区域中的单元。此外,在训练过程中逐渐增加丢弃单元的数量会带来更高的准确率,使模型对超参数选择具备更强的鲁棒性。大量实验证明,DropBlock 在正则化卷积网络方面性能优于 dropout。在 ImageNet 分类任务上,具备 DropBlock 的 ResNet-50 架构达到了 78.13% 的准确率,比基线模型提高了 1.6%。在 COCO 检测任务上,DropBlock 将 RetinaNet 的 AP 从 36.8% 提升到 38.4%。
与 dropout 类似,我们不将 DropBlock 用于推断。
DropBlock 是类似 dropout 的简单方法。二者的主要区别在于 DropBlock 丢弃层特征图的相邻区域,而不是丢弃单独的随机单元。Algorithm 1 展示了 DropBlock 的伪代码。DropBlock 具备两个主要参数 block_size 和 γ。block_size 是要丢弃的 block 的大小,γ 控制要丢弃的激活单元的数量。

我们在不同特征通道上对共享 DropBlock mask 进行了实验,也在每个特征通道上对 DropBlock mask 进行了实验。Algorithm 1 对应后者,它的效果在实验中也更好一些。
实验中,DropBlock 在大量模型和数据集中的性能大大优于 dropout。向 ResNet-50 架构添加 DropBlock 使其在 ImageNet 数据集上的图像分类准确率从 76.51% 提升到 78.13%。在 COCO 检测任务上,DropBlock 将 RetinaNet 的 AP 从 36.8% 提升到 38.4%。
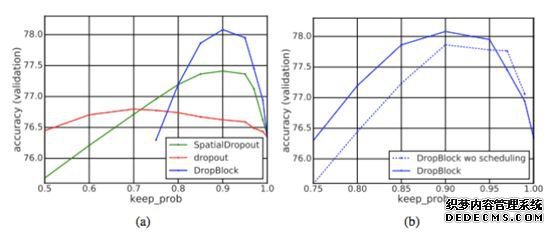
Scheduled DropBlock。我们发现具备固定 keep_prob 的 DropBlock 在训练过程中表现不好。最初 keep_prob 的值过小会影响模型的学习。而逐渐降低 keep_prob 的值(从 1 下降到目标值)更具鲁棒性,改进了大多数 keep_prob 的值。实验中,我们使用线性机制来降低 keep_prob 的值,其在很多超参数设置中都表现良好。该线性机制类似于 ScheduledDropPath。
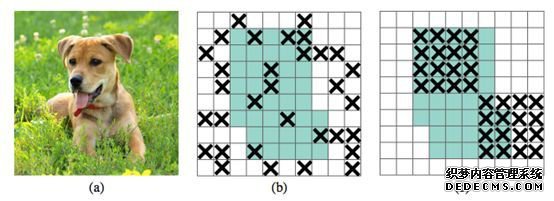
本论文介绍了一种 dropout 的结构化形式 DropBlock,对于正则化卷积网络格外有效。在 DropBlock 中,同一模块中的特征会被一起丢弃,最新网页游戏私服,即特征图的相邻区域也被丢弃了。由于 DropBlock 丢弃了相关区域中的特征,该网络必须从其他地方寻找证据来拟合数据(见图 1)。
设置 block_size 的值。在实现中,我们为所有特征图设置常数 block_size,无论特征图的分辨率是多少。当 block_size = 1 时,DropBlock 类似 dropout,当 block_size 覆盖完整特征图的时候,DropBlock 类似 SpatialDropout。