另一个问题是,在非完全信息环境下如何博弈。 AlphaGo 下围棋,是一个完全信息博弈(双方都能看到棋盘上的所有棋子的位置),但是基本上所有的游戏场景,以及现实的决策场景,都是不完全信息的。其实任何一个人做决策可能都是在不完全信息下做决策。我们提交的一些论文就是尝试把强化学习和博弈论结合起来,一起去研究,这个也是新的方向。

雷锋网 AI 科技评论:强化学习是近年来的人工智能研究热点,但是学习过程本身就有诸多困难,正如你们在介绍中说道「可复现性、可复用性和鲁棒性方面依然存在挑战」。那么你们选择强化学习作为自己的核心技术研发方向,可以谈谈有信心的理由吗?目前有哪些原创的技术成果吗?
深度强化学习+启发人类的决策智能,专访一家有愿景的中国企业「启元世界」
2019-01-11 13:04 来源:雷锋网 化学 /开发 /技术
袁泉,启元世界创始人 & CEO:曾担任阿里认知计算实验室负责人、资深总监,手机淘宝天猫推荐算法团队缔造者,打造了有好货、猜你喜欢等电商知名个性化产品,率团队荣获 2015 年双 11 CEO 特别贡献奖。加入阿里前,袁泉曾是 IBM 中国研究院的研究员,从事推荐等智能决策算法的研究,是 IBM 2011 年全球银行业 FOAK 创新项目发起人。在工业界大规模应用实践的同时,总结并发表了十余篇论文在国际顶级会议 ACM RecSys、KDD、SDM 等。袁泉拥有多项中美技术专利,长期担任 ACM RecSys、IEEE Transaction on Games 审稿人。启元世界是一家 2017 年成立的以认知决策智能技术为核心的公司,由前阿里、Netflix、IBM 的科学家和高管发起,多位名牌大学的博士和硕士加入,并拥有伯克利、CMU 等知名机构的特聘顾问。启元世界的愿景是「打造决策智能、构建平行世界、激发人类潜能」,团队核心能力以深度学习、强化学习、超大规模并行计算为基础,拥有互联网、游戏等众多领域的成功经验,受到国内外一流投资人的青睐。
说回决策智能,它是个比较通用的技术,这种辅助决策的能力可以泛化到很多行业,甚至包括网络智能―― 其实网络中的每一个节点也都是一个可决策的智能体,决策智能有很大的发挥空间。未来可能对于电信电力、网络智能相关的行业我们也会关注。
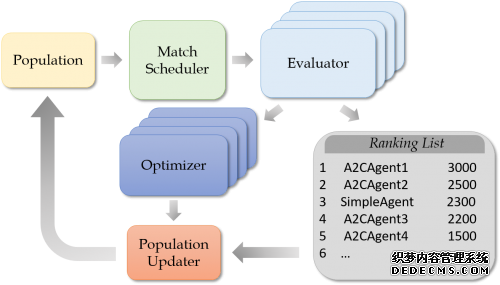
第二,支持复杂场景的多智能体联合训练。在多智能体博弈问题中,不同智能体之间的相互克制较为常见,其收敛可能性极为复杂。以炸弹人竞赛举例,在竞赛中,不同队伍的智能体风格迥异,有的善攻,有的善守。基于「鲶鱼效应」的思想(指透过引入强者,激发弱者变强的效应),启元决策智能平台在训练初期引入基于规则的高阶对手,激发初期较弱的智能体在与强者的对决中学会各种基本技能,迅速提升变强;随着训练阶段的深入,启元决策智能平台同时训练多个智能体,使其在激烈的相互对抗中完善自我。
雷锋网 AI 科技评论按:上次我们报道了来自中国的决策智能企业「启元世界」,他们凭借自己的核心技术深度强化学习和决策智能平台,在 NeurIPS 2018 多智能体竞赛「炸弹人团队赛」中获得了 Learning 组冠军。
其次,如果行进过程中确实有这种情况发生的时候,这个最大的原则肯定是保护人:保护人的生命,我觉得这应该是第一原则。这让我想到阿西莫夫的机器人三原则,其实自动驾驶汽车就是一个机器人,它在任何时候都要以不得伤害人的生命为第一原则。如果是要在行人的生命和乘客的一些小的损伤、安全性上面做一些取舍,我相信可能也应该遵从这种原则。
我们优势是基于创始人、创始团队过去十余年在国际一流的研究机构、互联网企业的经验,对世界范围内整个领域有深入的洞见和实践经验,清楚技术的边界和发展路径,与伯克利、CMU、纽约大学的许多知名专家学者都建立了深入的合作机制,能比较好的将决策智能的技术研发与前沿科研统一起来,兼顾商业化的落地场景。
雷锋网 AI 科技评论:对于人工智能决策,有一个常被谈起的设想问题是,假如一辆高速行驶的自动驾驶汽车面前突然冲出一个行人,减速避让可能会伤害到车内的人,而不减速避让则会伤害到这个行人。决策智能能否完美地解决类似这样的问题呢?
雷锋网 AI 科技评论:那么强化学习有机会全面替代监督学习吗?
第一,持续学习的能力。持续学习的能力是智能体训练中关键的一环。在训练阶段,智能体需要在学习新技能的过程中保留过去学会的技能,才能达到很高的水平。启元决策智能平台通过智能体群体匹配竞技的方式实现「自然选择」,从而达到持续学习的效果。在竞技过程中,强者留存,弱者被淘汰。在弱者被淘汰之后,空出来的位置被强者的克隆体代替,而强者的克隆体则根据新的超参设定持续进化。在固定计算资源预算的情况下,启元决策智能平台通过这套机制在探索新强者(exploration)和深挖旧强者(exploitation)之间平衡对计算资源的使用情况。
觉得有信心的理由的话,就是归根结底还是来自于团队和对强化学习的信仰。就像 AlphaGo 论文的一作以及主程序员、DeepMind 的科学家 David Silver 十多年前专门从英国跑到冰天雪地跟开辟了这整个领域的 Richard Sutton 学习强化学习。在这之前 David Silver 和 DeepMind 的另外一个创始人 Demis Hassabis 已经创办了一家电子游戏公司,十多年前就在探索《黑与白》这类基于 AI 的游戏。这都是他们对强化学习有信仰的证明。
出于这样的初心,我们希望 Build Intelligence ,打造决策智能; Incubate Worlds,构建平行世界,比如各种虚拟的游戏、虚拟的场景,甚至和 VR 结合起来的平行世界;Inspire People,通过决策智能帮助人、激发人的创造力。
雷锋网 AI 科技评论:最后一个问题,您曾经在阿里工作了较长时间,那么您离开阿里创业的动力和愿景是什么?
10个训练后的智能Reaper在环境中与玩家控制的10个Reaper对抗,表现出智能进退、追逐、分组合围、利用地形腾挪跳跃的能力
2018 年我们已经尝试把一些技术商业化,目前也取得了不错的营收。2019年,启元世界计划发布第一版启元决策智能平台型产品,为更多行业客户、终端用户带去高体验的服务。
