7.2. 小表复制(主数据复制同步):同时可以有选择的将一些不经常更新的,数据量比较小的元数据表复制到全部的节点上。
当我们的系统规模越来越大,从几台服务器扩展到几十台、几百台、上千台,传统的烟囱式的、大集中式系统架构,逐步演进为服务化SOA、分布式的系统架构:
1. DRDS基本原理-读写分离:
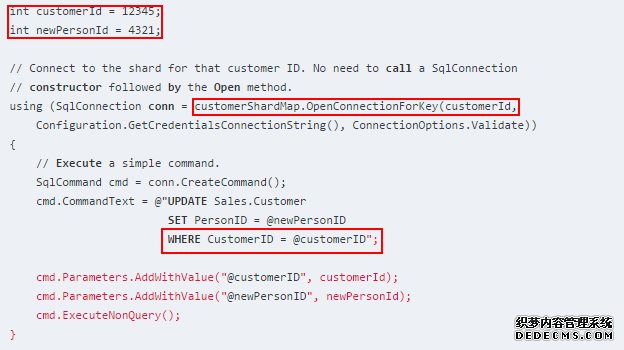
假设将一个请求传入应用程序。基于请求的分区键值,应用程序必须根据该键值判断正确的数据库。接着,它会与数据库建立连接来处理请求。借助数据依赖路由,
3. 多分片查询:多分片查询用于诸如数据收集/报告等需要跨多个分片运行查询的任务。(相比之下,数据相关的路由会在单个分片上执行所有操作。)
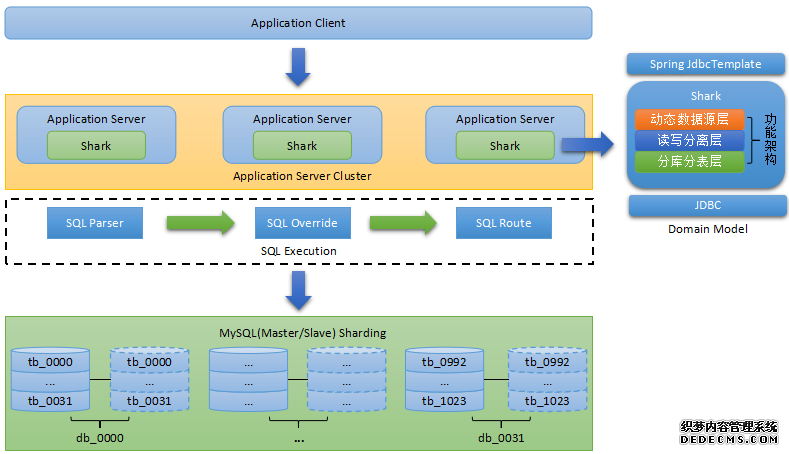
动态数据源的无缝切换;
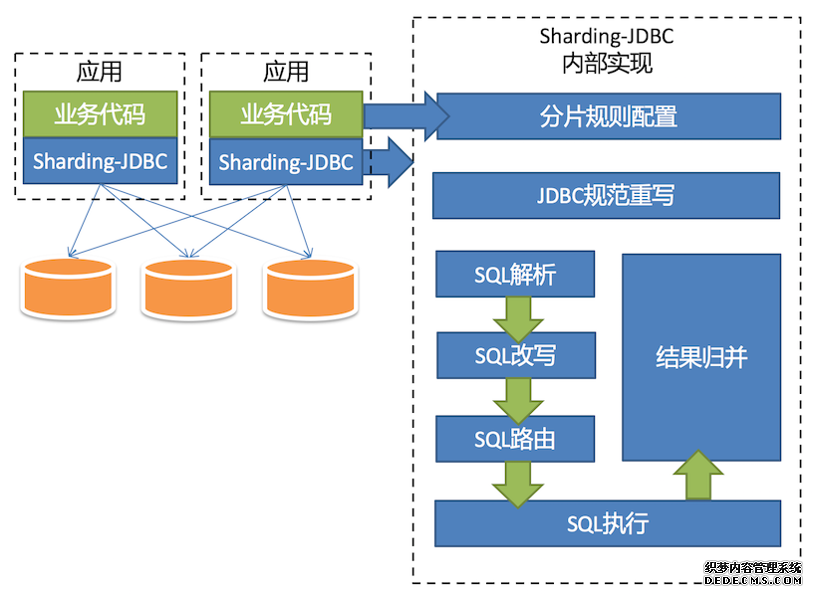
Sharding-JDBC是当当应用框架ddframe中,关系型数据库模块dd-rdb中分离出来的数据库水平扩展框架,即透明化数据库分库分表访问。
同样,也有很多限制:
四、Shark:分布式的MySQL分库分表中间件
3. DRDS基本原理-SQL路由
基于velocity模板引擎渲染内容,支持sql语句独立配置和动态拼接,与业务逻辑代码解耦;
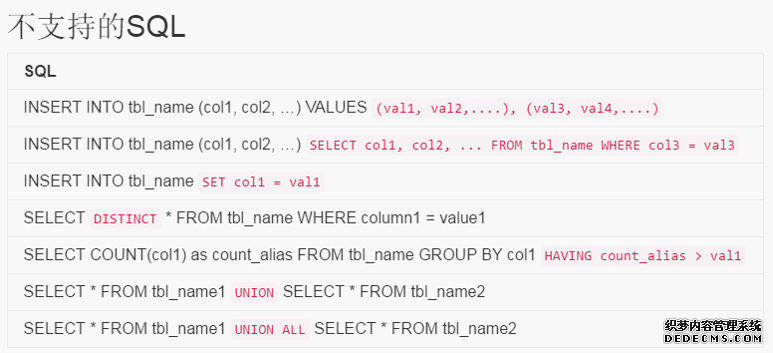
5. DRDS支持的SQL语法
Sharding-JDBC定位于日常数据库CRUD操作,目前仅针对DQL和DML语句进行支持。
此Shark非工作流Shark,是云集主要的分布式数据访问框架,也是Java技术路线,它是一个应用程序层的数据访问框架。
.dataSourceRule(dataSourceRule)DRDS 目前定位成一个中间件(前身是TDDL),在业务应用和RDS(关系型数据库服务器)之间,本身不承担数据存储,
2. 数据路由:使用查询中的数据将请求路由到相应数据库的功能
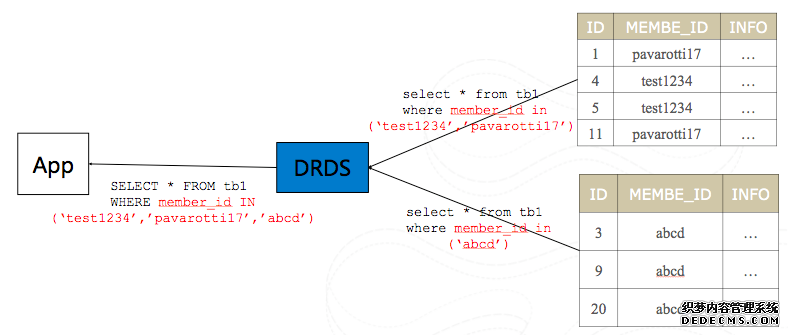
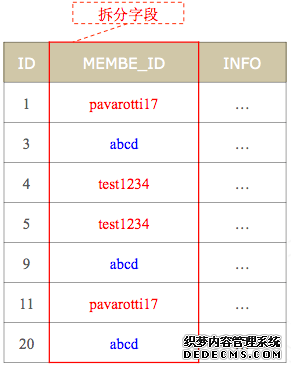
当用户SQL到DRDS时,DRDS会解析整个SQL含义,然后按照拆分字段的值和执行策略将SQL路由到对应分区进行执行。
如果一个SQL对应多个分片数据执行,DRDS会将各个分片返回的数据按照原始SQL语义进行合并。
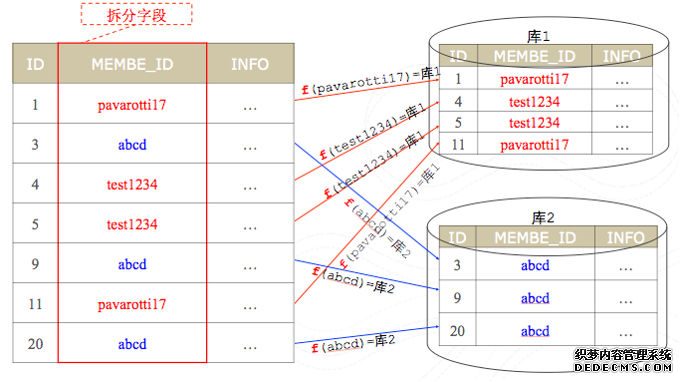
或者按照商品进行切分,那么join就会物理上的发生在同一个机器上,DRDS能够很轻松的保证所有在单机发生的join查询,物理上都能够查出数据,
将参与分片中的结果合并到一个总结果集中。该功能是通过该客户端库处理多个任务公开的,其中包括连接管理、线程管理、故障处理和中间结果处理。
不建议、不支持多表查询,所有多表查询sql,务必全部打散为单条sql逐条执行;
这个系列的第一篇以"华山网页游戏私服" 开始吧,细数各门各派的看家本领(分布式数据访问服务框架),一较高低!
三、当当Sharding-JDBC
对于非常复杂的SQL,可以通过注释的方式,直接告知DRDS切分条件,这样就可以绕开SQL解析器进行查询。
跨分片操作, UPDATE A,B set A.s = B.s+1 WHERE A.ID = B.NAME , 非拆分字段之间的跨库JOIN
2. 业界主流的分布式数据访问组件主要面向CRUD操作,复杂查询的实现依赖于数据仓库、分析型数据库、大数据分析等技术来实现
业界主流的互联网架构中,分布式服务框架、分布式数据访问服务、消息队列服务、服务网关(API)、分布式事务等都是核心的组件和框架。
一、微软Azure SQL

总结:阿里的DRDS还是非常强大的,依靠MySQL原生的Replica技术+SQL路由解析+内存数据合并,日常的MySQL分库分表、读写分离等大部分场景都能支持。
这样,大表join小表的时候,就从一个分布式join变为了本地join,当然,这种过程需要一定的代价,也就是元数据表内的数据更新,
暂不支持非where条件的correlate subquery
子查询限制
sql语句的第一个参数务必是shard key;
跨库事务, 比如两次UPDATE不在一个分片上
1. 分布式数据访问组件基于物理上的数据库分库分表,主要解决数据库的横向扩展问题
业务零侵入,配置简单;
分库分表的部署、管理、集成的确非常方便,原生支持。但是本地化私有云环境下,SQLServer的分库分表就需要自己搞了。
shard key必须是整数类型;
综合起来说,分布式数据访问服务是大规模分布式应用的必备中间件,技术复杂度和难度都很高,涉及的技术栈比较多,同时比较深,我们会继续深入研究,
7.3. 在线查询与离线查询分离:对于复杂的大表和大表的分析和统计类查询,阿里内部推荐采取专门的分析引擎来获取报表数据,比如使用ODPS等,
preparedStatement.setInt(1, 10); 6 preparedStatement.setInt(2, 1001);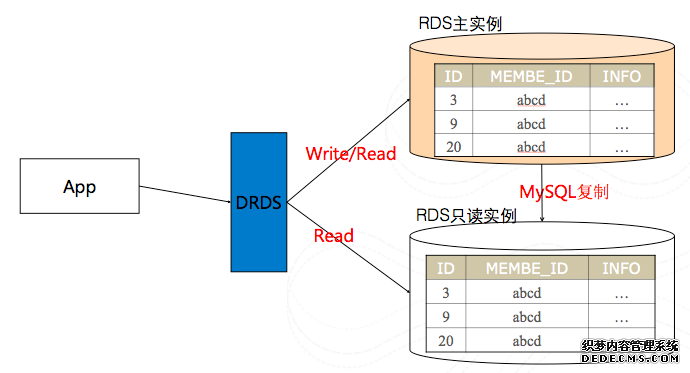
也可支持多分片键共用
编程示例:
只负责解决分布式情况下数据操作路由、执行、数据处理等功能。主要支持的数据库是MySQL。
提供多机sequenceid的API支持,解决多机sequenceid网页游戏私服推荐;
String sql = "SELECT i.* FROM t_order o JOIN t_order_item i ON o.order_id=i.order_id WHERE o.user_id=? AND o.order_id=?";丰富、灵活的分布式路由算法支持;
DRDS的使用与MySQL非常接近,建实例、建库、建表、SQL操作,唯一比较大的区别在于水平拆分模式下,DRDS对于建表需要指定拆分字段(类似索引),
5. 分区键的设计非常重要,阿里的实践值得借鉴:用户和商品两个维度,满足不同用户的需求
不支持强一致性的分布式事务,建议在业务层依赖MQ,保证最终数据一致性;

支持读写分离
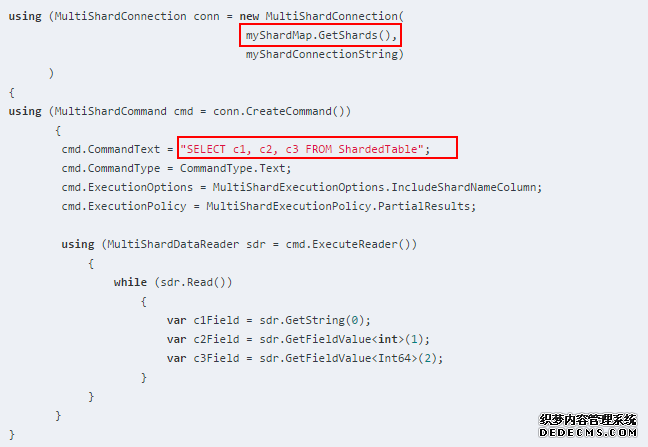
能够通过对应用程序的分片映射的单个简单调用打开连接,进行数据操作:
以支撑我们超大规模的系统。
2. DRDS基本原理-水平拆分
} 9 ResultSet rs = preparedStatement.executeQuery(); 8 {DRDS 对于单机事务完整支持,也就是业务中一个事务中的各个SQL最终都落到同一个数据库即可保障强一致,
此功能支持使用成百上千个 AzureSQL 数据库,轻松地开发数据分区应用程序。然后,可以使用弹性作业帮助简化这些数据库的管理。
对于sql进行类型判定,如果判定为读取操作,则按照用户设置的读权重进行sql路由,到主实例或者到只读上进行sql操作。
.build(); 2 DataSource dataSource = ShardingDataSourceFactory.createDataSource(shardingRule);提供自动生成配置文件的API支持,降低配置出错率;
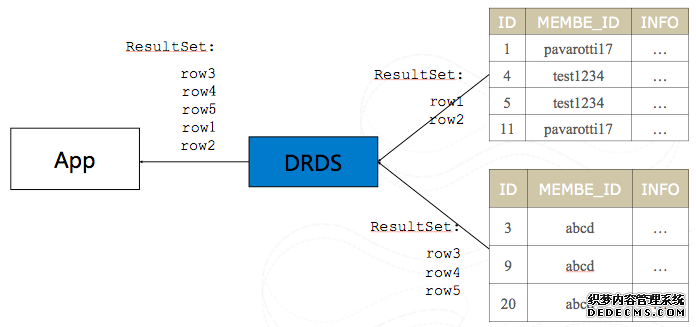
4. DRDS基本原理-数据合并:
6. DRDS不支持的SQL语法:
搞了这么多年.Net,ORMapping(EF、Hibernate、MyBatis),有必要搞一个“分布式数据访问服务”的技术专题,作为总结和技术分享。
7. 还有分布式事务问题需要解决,阿里有个TXC,可以学习了解借鉴。
提供内置验证页面,方便开发、测试及运维人员对执行后的sql进行验证;

这类查询使用传统数据库架构,在数据量非常巨大的时候,很可能会影响线上的应用,因此阿里建议将在线和离线查询分开。
while(rs.next()) {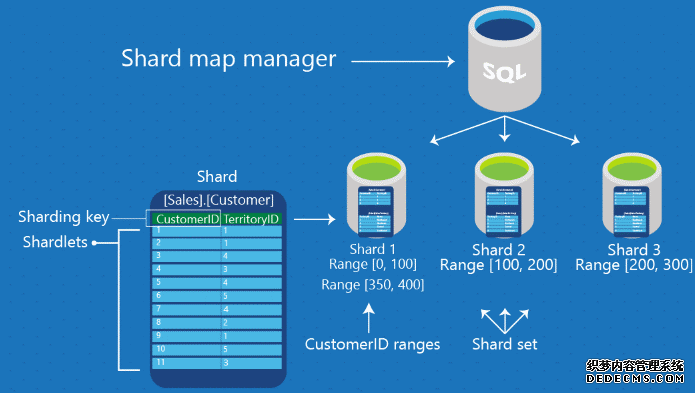
6. 分库分表后的复杂查询是一个大的技术挑战:需要解决跨库Join、跨多个Shard查询合并、存储过程、综合BI查询等等,可能需要引入数据仓库和大数据技术来实现
最多可以查询数百个分片
完善的技术文档支持;
.tableShardingStrategy(new TableShardingStrategy("sharding_column", new XXXShardingAlgorithm()))).tableRules(tableRuleList)
}
总结:微软的Azure SQL是一个PaaS层的数据访问服务,需要将本地数据库迁移到Azure SQL,即云端SQLServer中,
对于复制的综合查询,咨询了当当的架构师团队,他们也在计划通过离线分析和大数据分析来实现,不过其实时性和数据的准确性是一个挑战。
只要带上这个拆分字段,SQL只会在部分数据分片上执行,从而加速SQL执行速度。
通过上面四个主要的分布式数据访问服务/框架的比较,我们深入研究了分布式数据访问技术,有以下收获分享给大家:
当一个请求涉及多个(或所有)分片时,多分片查询将生效。多分片查询在所有分片或一组分片上执行相同的 T-SQL 代码。使用 UNION ALL 语义,
4 Connection conn = dataSource.getConnection(); 5 PreparedStatement preparedStatement = conn.prepareStatement(sql)) {目标是设计一套.Net版本的分布式数据访问服务。有兴趣的小伙伴,可以一起搞。
1. 分片映射管理器:分片映射管理器是一个特殊的数据库,它维护一个分片集中有关所有分片 (数据库)的全局映射信息。
对于跨数据库的分布式事务,DRDS提供最终一致分布式事务给业务使用,目前处于内测阶段。
3. Sharding策略和SQL路由是实现分库分表的关键技术,其中Sharding的粒度:主要有两种:Database(数据库) 和 Table(表),即分库和分表
从框架名字看,肯定是Java技术路线的,官方的说明中,Sharding-JDBC功能灵活且全面:
非proxy架构,应用直连数据库,降低外围系统依赖所带来的宕机风险;
对于sql进行类型判定,如果判定为读取操作,则按照用户设置的读权重进行sql路由,到主实例或者到只读上进行sql操作。
不是所有的join都能够支持,例如对于大表之间的join,就因为执行代价过高,速度过慢而被DRDS限制,但大部分的join的语义,支持以最高效的方式完成。
.databaseShardingStrategy(new DatabaseShardingStrategy("sharding_column", new XXXShardingAlgorithm()))支持柔性事务(目前仅最大努力送达型)。
使用 Azure SQL 数据库的可缩放工具和功能,可以轻松地横向扩展数据库。特别是可以使用弹性数据库客户端库来创建和管理扩大的数据库。
受限于分布式事务
可能在一小段时间(50~100ms)后才能在分库内看到。
拆分键变更, UPDATE A SET A.ID = 1 WHERE XXX, ID为拆分字段
System.out.println(rs.getInt(1));二、阿里分布式关系型数据库服务DRDS——云端数据库PaaS服务
它包含了三个核心组件:分片映射管理、数据路由、多分片查询
分片策略灵活,可支持=,BETWEEN,IN等多维度分片,
最近研究了业界主流的分布式数据访问服务,做了一次横向对比和分析。基于对比做技术选型、验证,目的就是要设计一套.Net版本的分布式数据访问组件。
在数据层面,应用层面,访问层面和查询方面,全都以分布式的结构来搭建,使整个系统不存在性能和横向扩展的瓶颈,实现系统的弹性伸缩和横向扩展,
DRDS处理join的原则非常简单:尽可能让join发生在单机。
项目的Git:https://github.com/gaoxianglong/shark,个人要支持一下,希望能继续增强改进。
这就意味着参与join的多张表按照同一个维度进行切分。例如,一个用户有多个商品,每个商品都有自己的商品特征。这时候,如果需要join,可以将所有数据按照用户,
缺省支持基于zookeeper、redis3.x cluster作为集中式资源配置中心;
4. Sharding策略主要有以下几种:时间范围、ID哈希、地理区域、Hash分区、枚举分区、表达式计算分区等等
五、总结
DRDS中的数据是按照拆分字段值,加上特定的算法进行计算,根据结果存储数据到对应分片。
DRDS有着比较完整的MySQL SQL兼容性
站在巨人的肩膀上(springjdbc、基于druid的sqlparser完成sql解析任务),执行性能高效、稳定;
跨分片操作, INSERT A SELECT B WHERE B.ID > XX , 跨库导入导出数据
7.1. 按照同一个维度进行切分:如果能够让join物理上发生在单台机器上,那么任何一类的复杂查询都是可以直接支持的。一般而言,
Shark的技术优点: